CheerpJ is a WebAssembly-based JVM that runs fully client side in the browser. It supports Java applications, legacy applets and libraries, with no need for compilation, server backends, plugins, or post-processing steps.
CheerpJ was originally released in 2017, quickly becoming Leaning Technologies’ most widely known and successful product. In the last six years, we collected a vast amount of feedback from users that led us to perform a full rewrite of CheerpJ, which we announced in May.
CheerpJ 3.0 (old version) introduces a completely new JIT-based architecture which makes the tool faster, more usable and much more powerful. CheerpJ 3.0 was released in January 2024, with support for Java 8. Thanks to its new runtime architecture, subsequent releases of CheerpJ will expand its support to more recent LTS releases of Java, starting from Java 11.
CheerpJ 4.1 Released! Check out the latest version of
CheerpJ![]() !
!
What can CheerpJ do?
CheerpJ is a JVM implementation that runs in any modern browser using standard Web technologies, particularly WebAssembly, JavaScript, and HTML5.
CheerpJ can be integrated into a web page like any JavaScript library, by simply adding a <script> tag. It requires no custom executable component, plugin, or server-side backend.
It exposes a simple API for executing standalone Java applications, applets, Java Web Starts, and Java libraries - entirely in the browser.
Being a collection of static assets, it is easily self-hostable, and we provide a cloud version under the CheerpJ Community Licence (free to use for personal projects and technical evaluations).
No modifications needed
CheerpJ can run unmodified Java applications, applets and libraries from JAR files. It does not require access to the source code, or specialized compile-time tools. This is especially useful when running legacy applications, whose source code might not be available, or applications based on 3rd party commercial libraries.
Developers can use their existing JAR files with no changes to your building process. Obfuscated and minimized artifacts are fully supported .
CheerpJ can run extremely large and complex applications: we recently stress-tested it on IntelliJ IDEA 2019![]() , which ships ~400MB of JAR files.
, which ships ~400MB of JAR files.
Full Java support
CheerpJ supports multiple processes and threads. It can run a single or multiple independent Java applications, each consisting of multiple threads. Synchronization features are supported.
CheerpJ provides full support for ClassLoaders. Java classes are loaded following the same approach as native Java implementations. The correct ClassLoader is invoked, depending on the current execution context, which internally resolves the correct Java bytecode using arbitrary logic. User-provided ClassLoaders are also supported, including customs ones implementing encryption or obfuscation.
Reflective access to methods and fields is achieved via metadata provided by Java bytecode. After a ClassLoader resolves the bytecode CheerpJ will store it not only for the purpose of running and compiling Java code, but also to implement reflection. Annotations are also supported.
Extensive runtime and system access
CheerpJ provides a completely unmodified build of OpenJDK. Specifically, the most recent OpenJDK 8 revision. The architecture is designed to support multiple versions of Java, as well as custom runtimes. Future versions of CheerpJ will support Java 11, and newer LTS Java versions.
Graphical applications, including Swing and AWT are supported. Swing ones, being platform independent, will render exactly as they do in native. Swing Look&Feel is also supported, including 3rd party ones. Multi-window applications are supported, with keyboard focus being managed as expected. Integration with the system clipboard can be enabled via an initialization option.
CheerpJ provides advanced, bidirectional Java-JavaScript interoperability: You can access JavaScript and the DOM from Java by implementing native methods directly in JavaScript. You can also interact with Java methods, objects and arrays directly from JavaScript by using the new cheerpjRunLibrary API.
How does CheerpJ 3.0 work?
The CheerpJ 3.0 architecture was engineered to solve the limitations present in CheerpJ 2.x and to take advantage of the unique experience about in-browser JIT-ting that we gathered from our work on CheerpX: a WebAssembly-based virtual machine for x86 binary code.
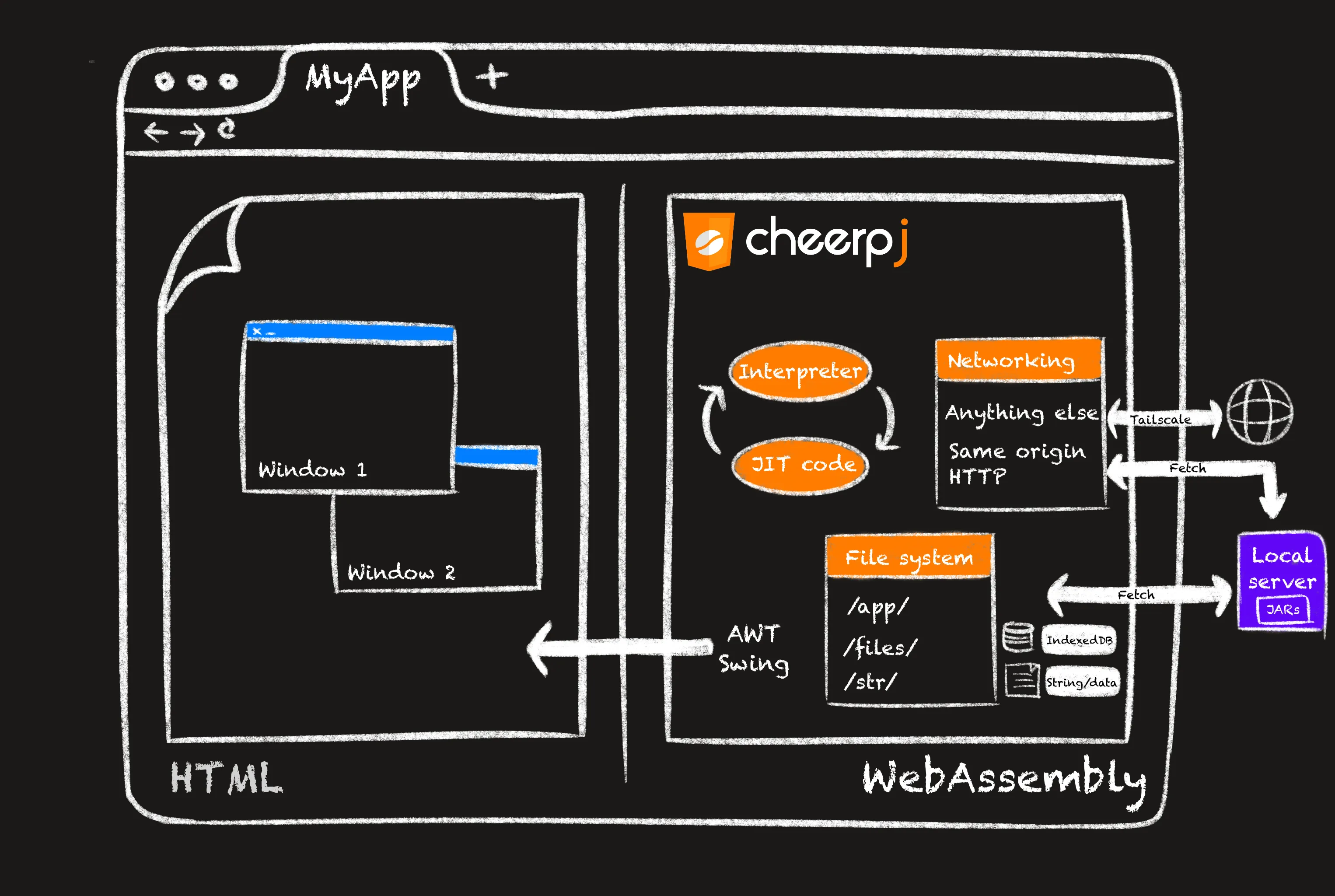
At a high level, CheerpJ is composed of the following building blocks:
- A JVM implementation: Written in C++ and compiled to WebAssembly. The CheerpJ JVM implements a 2-tier execution mode. Code runs within an interpreter before being Just-In-Time compiled to optimized JavaScript. The interpreter does not only deal with initialization and rarely-used code, but also gathers information necessary for JIT-ting. Generated code is very efficient, and the internal optimizer can, among other things, inline and devirtualize calls, which is extremely important for a language such as Java.
- A virtualized window manager: Which supports AWT/Swing. Each window is converted to a hierarchy of HTML elements and HTML5 canvases.
- A virtualized File System: CheepJ provides multiple filesystem backends to accommodate different application needs, including access to server-hosted files and persistent local storage.
- Networking support: For same-origin HTTP/HTTPS requests, CheerpJ will be able to transparently use
fetch. More generalized networking is supported via Tailscale, a VPN technology using WebSockets as a transport layer. It can support many different networking scenarios, including access to private network services, peer-to-peer connections between users and access to the wider internet via a user/application provided exit node.
All these capabilities are implemented as pure WebAssembly or JavaScript. CheerpJ requires no binary component, plugin or non-standard browser configuration.
How does this compare to CheerpJ 2.x?
When designing the new CheerpJ 3.0 architecture, we had the objective of making a drop-in replacement for CheerpJ 2.3. With some minor exceptions (improved APIs that led to some others being removed), this objective was achieved.
Important information for CheerpJ 2.x users
If you used CheerpJ 2.x in the past, these are the most significant changes you should be aware of:
- No Ahead-Of-Time compilation: To achieve good performance, CheerpJ required you to post-process JAR files with a custom binary compiler. The compiler would generate a
.jar.jsfiles for each input JAR. CheerpJ 3.0 features an advanced JIT engine that can, even in this first release, generate better-performing code than CheerpJ 2.3 ever could. Removal of.jar.jsfiles also significantly decreases how much data needs to be downloaded during application startup. - Actual support for ClassLoaders: CheerpJ 2.3 had very limited support for ClassLoaders. As a consequence of requiring AOT compilation of
.jar.jsfiles, it could only support the standard one provided by OpenJDK. CheerpJ 3.0 radically improves the status-quo by properly using ClassLoaders as expected by Java. - Breaking changes
- The API is not exposed until
cheerpjInitis called and its Promise resolves. cjNew/cjCallJS APIs replaced with library mode: CheerpJ 2.3 offered some limited and cumbersome APIs to use Java code from JavaScript. These have been removed in favor of library mode, which is more powerful, easier to use and better specified.- Removal of specialized
CheerpJWorkerAPI: It is now possible to use CheerpJ directly from JavaScript Web Workers, simply by callingimportScriptsto include the CheerpJ 3.0 loader. Full applications can now be run within Workers, as well as libraries in library mode to offload computation workloads. - Removal of
cheerpjRunJarWithClasspath: When usingjava -jar, the JAR file is the source of all user classes, and any other class path settings are ignored - so this API was not very useful. - Removal of the CheerpJ-DOM Java API: When we first released CheerpJ we planned on providing full access to the DOM APIs directly from Java, but the feature was never complete. We have removed this API in favor of the new
nativefeature, which makes it possible for third party libraries to implement something similar to the legacy CheerpJ-DOM in a more robust manner. A viable solution was already contributed by one of our users.
- The API is not exposed until
Library mode: A new way of using Java libraries in web apps
CheerpJ 3.0 introduces a new syntax to directly use Java methods, objects and arrays from JavaScript. This new API has been designed taking advantage of async/await to feel more natural to use, without sacrificing any flexibility.
To illustrate this new feature a code snippet is worth a thousand words.
async function libraryModeTour() { await cheerpjInit();
// Create a library mode object const lib = await cheerpjRunLibrary("/app/");
// Resolve the Java classes we are going to use const ArrayList = await lib.java.util.ArrayList; const Point = await lib.java.awt.Point; const System = await lib.java.lang.System;
// Create a new list object const points = await new ArrayList();
// Create 4 point objects for (let i = 0; i < 4; i++) { // Allocate the point const p = await new Point(i, 0);
// Add the point to the list await points.add(p); }
// Convert to list to an Object[] array const a = await points.toArray();
// Iterate on the array and set y = x for (const i = 0; i < a.length; i++) { // Fields can be read and written directly a[i].y = a[i].x; }
// Convert all the elements to Strings for (const i = 0; i < a.length; i++) { // Java arrays can be read and written directly a[i] = await a[i].toString(); }
// Print them out for (const i = 0; i < a.length; i++) { // Static fields can be accessed too await System.out.println(a[i]); }}CheerpJ library mode can be used to integrate powerful Java libraries into your Web application. As a practical example, these few lines of code make it possible to generate a PDF from JavaScript using the popular iText library:
async function iTextExample() { await cheerpjInit();
const lib = await cheerpjRunLibrary("/app/itextpdf-5.5.13.3.jar");
try { const Document = await lib.com.itextpdf.text.Document; const Paragraph = await lib.com.itextpdf.text.Paragraph; const PdfWriter = await lib.com.itextpdf.text.pdf.PdfWriter; const FileOutputStream = await lib.java.io.FileOutputStream;
const document = await new Document(); const writer = await PdfWriter.getInstance( document, await new FileOutputStream("/files/HelloIText.pdf") );
await document.open(); await document.add(await new Paragraph("Hello World!")); await document.close(); await writer.close();
const blob = await cjFileBlob("/files/HelloIText.pdf"); const url = URL.createObjectURL(blob); pdfDisplay.data = url; } catch (e) { const IOException = await lib.java.io.IOException;
if (e instanceof IOException) console.log("I/O error"); else console.log("Unknown error: " + (await e.getMessage())); }}The new library mode API is also used for native methods implemented in JavaScript. A native is effectively just a shorter library mode session.
What can I do with CheerpJ?
Use cases
You might be wondering what use cases can CheerpJ support:
- Restoration of legacy gaming, educational or personal content: Especially if packaged as applets, bringing them back to life with CheerpJ is just a matter of including the loader and calling a single line of JavaScript. Try it now.
- Modernization of enterprise software: This includes Oracle Forms, EBS and similar Java based enterprise solutions, that are still widely used in Enterprise settings.
- Building Web Applications with Java libraries: CheerpJ can bring the power of Java libraries to Web apps. Thanks to library mode, Java libraries can now be integrated in Web applications via CheerpJ, rather than requiring a server-side component to run them.
- Fully client-side Java development environments and playgrounds: The
javaccompiler is itself written in Java and can run with CheerpJ. We showcase this in our JavaFiddle playground and the full source code is available if you want to delve deeper.
For further inspiration, take a look at what our community has already built.
Licensing
CheerpJ is free to use for personal projects, including those that generate revenue, and for technical evaluations. An overview of licensing is available here![]() .
.
What’s next for CheerpJ?
CheerpJ 3.0 is the most advanced solution for running large-scale Java applications in the browser.
We are very proud of what we have achieved, nevertheless there are currently some limitations that our users should be aware of:
- No access to user filesystem: For obvious security reasons Web applications do not have direct access to the local machine filesystem. Access can be provided to specific files, or directories with the newer FileSystem API. CheerpJ does not currently support an integrated user experience for Java applications to access such files, but the problem can be worked around via JavaScript code and the
/str/filesystem. We have plans to to implement more backends in the future to allow access to JavaScript Blobs, FileSystem API and cloud storage solutions such as Google Drive and Dropbox. - Java 8 only: The new CheerpJ 3.0 architecture is engineered to fix the gap with modern Java versions quite easily. We target supporting Java 11 (and possibly more) with the future CheerpJ 3.1 release. The architecture makes it possible to build specific past revisions for customers that have requirements from either dependencies or certifications.
- No support for third-party JNI components: There are a few large scale Java apps that cannot run in CheerpJ at this time since they depend on binary libraries. The most notable of these is Minecraft, which uses LWJGL. In the future we plan to release our JNI implementation to the public, allowing users to build their own WebAssembly JNI modules from C/C++.
- WasmGC support: The most keen reader might be wondering how the recently standardized WasmGC extension to WebAssembly impacts our work. As things stand we don’t think WasmGC will be necessary to reach a satisfactory level of performance, but it’s possible that our evaluation will change in the future. In any case, if CheerpJ will eventually introduce WasmGC as a JIT target, it will be a purely internal implementation detail. From the point of view of the user nothing will change besides a performance improvement.
Get started
You can use CheerpJ by simply adding a script tag to any HTML page:
<script src="https://cjrtnc.leaningtech.com/3.0/cj3loader.js"></script>For additional information please refer to our fully revamped documentation.
CheerpJ is a product built with passion by our talented team in Amsterdam (NL) and Leeds (UK). Try it out and let us know what you think!